Recently I rebuilt my home CentOS server which I use to run some home media services and keep up on my journey to learn linux. Everything was going well, I moved a few services into docker containers and everything not in a container was installed through package managers.
After a few days I noticed the media service plex would occasionally stop. Reviewing the systemd logs showed it was being killed presumably to allow a yum update to succeed. Oh, “that’s no problem” I thought, “I’ll just edit the systemd unit file to have the appropriate restart always instructions”. Well, I did that and a few days later when my wife and I went to watch a movie the plex media service wasn’t running again.
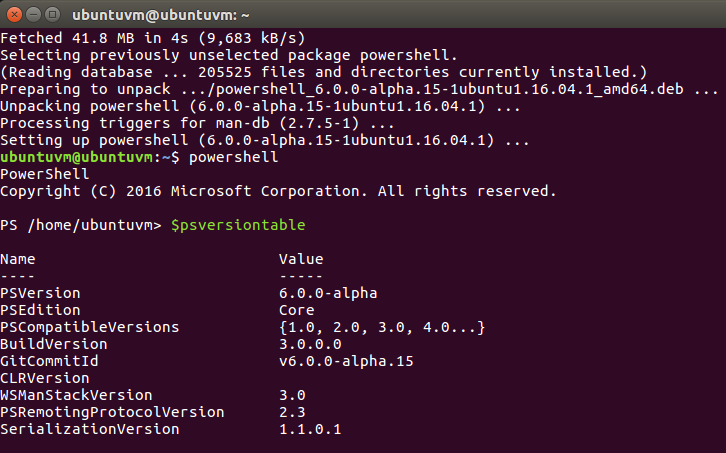
I spent a few minutes thinking on how I wanted to proceed from here and decided I would look at solving the reoccurring problem with PowerShell (Core) on linux. I got the repo configured and powershell installed via yum then started on my task to keep the plex service running.
Once PowerShell was installed I launched pwsh from terminal and tried Get-Service. I was greeted with this error.
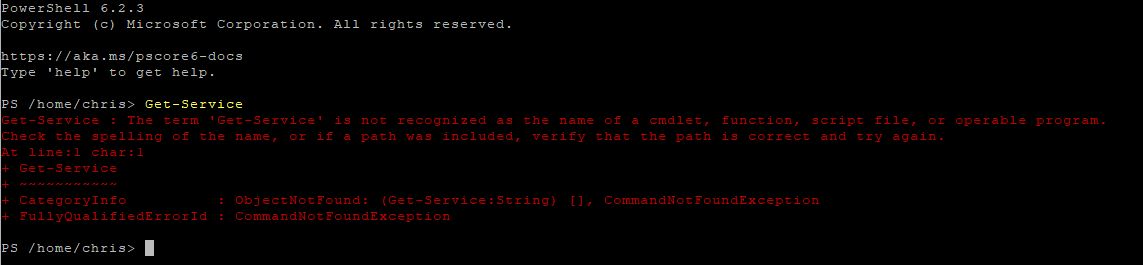
Well it looks like PowerShell Core does not support systemd or have the ‘*-Service’ cmdlets on linux. Not to be deterred, I decided I could attempt to parse text to get the job done like a “true linux admin”. A little of what Jeffrey Snover referred to as “Prayer-Based Parsing” in the Monad Manifesto…
5 minutes later I had a script that got the job done and could handle restarting plex if it was ever stopped in the future.
Let’s walk through the code.
Line 1 gets the services output then filters / greps the results and only returns the service I care about which is plex. If I had multiple services that shared a name then I could be more precise and ask for the individual service status directly but for now there is no need. I checked the output of systemctl with plex running and with plex stopped and notice there is no output when the service is stopped. When the service is running the following text is returned:
|
1 |
plexmediaserver.service loaded active running Plex Media Server |
Further inspection of the stopped/failed service state shows the string variable will not be null but it also won’t contain any string data. With this in mind, line 2 checks to see if the $plexstatus string variable is 0 characters. When it is 0 characters it will then set the boolean variable $startplex. This boolean will later be used to determine if the script will try to start the service.
To handle the expected condition of the plex service running we can check the output from systemctl and ensure the output indicates that plex service is running. This is where the prayer-based part comes in. Since there are no service objects and state properties available my approach is to fall back to string manipulation. Line 3’s success is very dependent on the text structure returned from the systemctl call. It is also going to use indexes after string splitting which will error if the split does not succeed and there is no resulting array elements that align with index. This is all very sloppy and error prone so it is placed in a try catch block to make sure if the prayer based parsing errors the script still has a path forward. The catch block will set the boolean to try to start the plex service instead of throwing an indexing error.
On line 5, this is a happy path check to make sure the output that has been parsed above contains the word running. If the value is anything but ‘running’ the boolean to start the plex service will be set.
Starting on line 6, the script will start the plex service if any of the failure conditions were met and then save some timestamped log data for future reference. A completely unnecessary else condition with an even more unnecessary Write-Output command brings it home.
Wrapping it all up, the script is set to run in a cronjob every few hours.
I’m sure there are much better ways to do this with standard *nix command line tools but by sticking with what I already know I was able to come up with a solution to my problem in a short period of time using PowerShell.