The other day I needed to launch some one-off Fargate / ECS container tasks with PowerShell. The documentation covered most of what I needed but I could not find any examples on how to override environment variables sent to the container task.
I only needed to change one environment variable so creating a whole new task definition seemed overkill for this purpose. After some trial and error the below code helped me get the job done.
If this helped you out please let me know in the comments. Feedback will motivate me to share solutions on this site more often.
Its been a while since I’ve posted here. I needed to set default encryption on a bucket in an account that was not being managed by cloudformation and was not making use of kms. Here is the PowerShell that worked since google came up empty for me!
I often see folks looking to get started with source control for their PowerShell scripts. There are a variety of free options out there but the choices get a bit limited when you need private repositories where code remains confidential. If you are like me a lot of your older code might be job specific, contain credentials, or perhaps you never even intend to share your code. None of those reasons are blockers for getting started using source control.
Here is a step by step walk through of using AWS CodeCommit and Git for Windows to make your first private Git Repo.
AWS CodeCommit
AWS CodeCommit is a service which provides fully managed, highly scalable source control and its currently free indefinitely for personal use if you stay under 50 GB stored, 5 user accounts, and 10,000 requests per month. Code is stored in AWS and automatically encrypted at rest. Think of it as private git repositories as a service.
There are a few methods which can be used to access CodeCommit. This guide will focus on HTTPS access with Git credentials instead of using IAM credentials directly. Using HTTPS leaves local Git able to interface with other Git repositories seamlessly.
Creating Your AWS CodeCommit Git Credentials
Assuming you already have an AWS account, navigate to the console and sign in. You can use that link to sign up for a new account and take advantage of AWS’ free tier if you are a new customer.
The first step after logging in is to create a new IAM user which will access the CodeCommit service. CodeCommit cannot be accessed over HTTPS from the root account. Head on over to the IAM console.
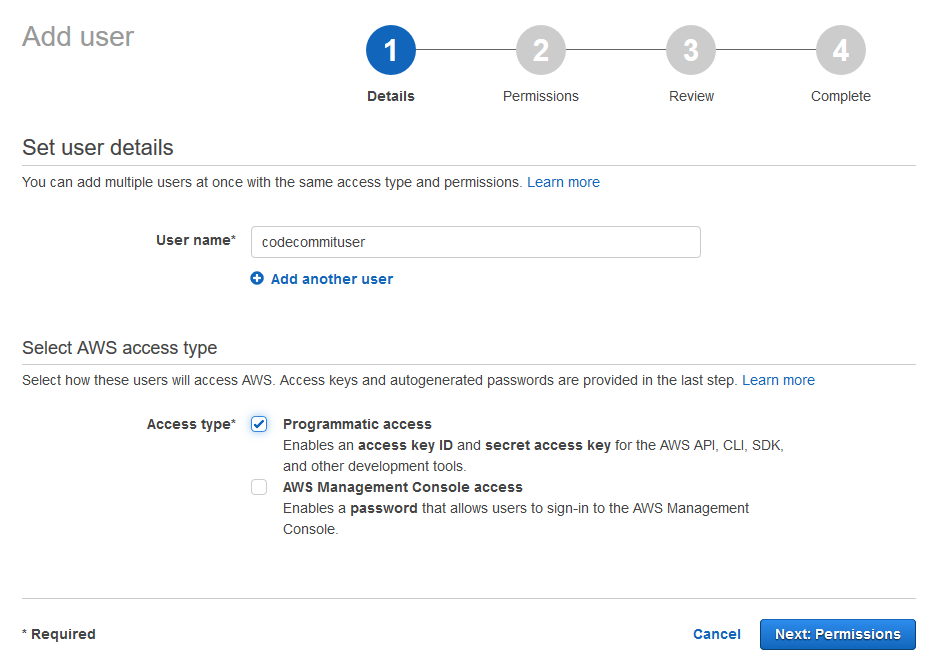
Within IAM create a new user. I’ll call this user codecommituser and check the box for Programmatic access.
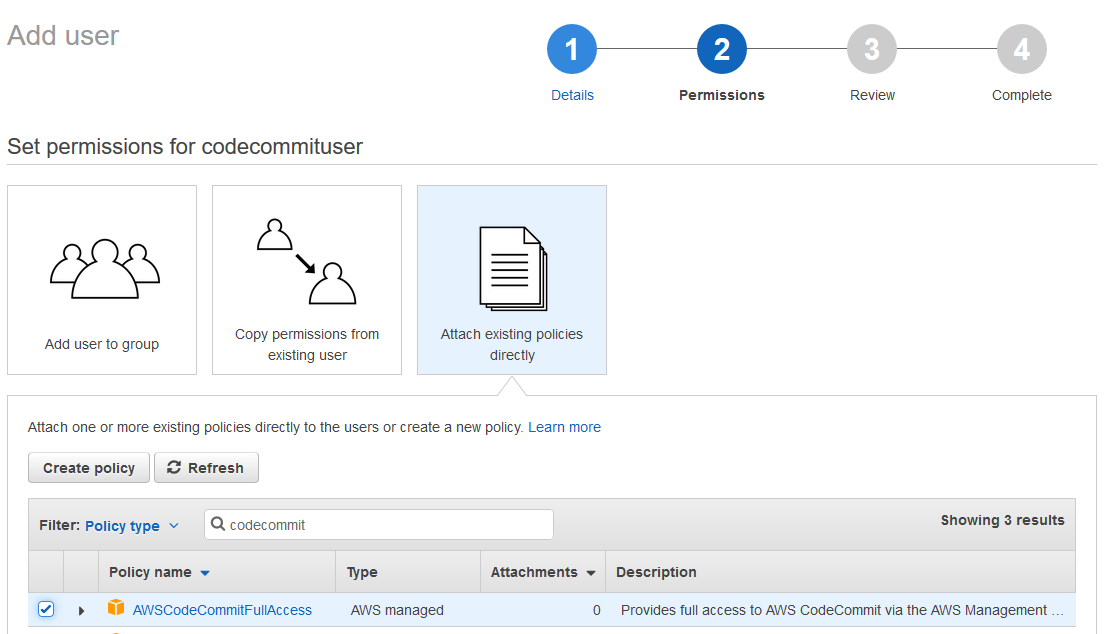
On the permissions page choose “attach existing polices directly” and search for codecommit. I will choose AWSCodecommitFullAccess but another option would be the AWSCodeCommitPowerUser policy which restricts repository deletions.
At the end of the add user wizard IAM credentials are presented for this user. These credentials are not needed so go ahead and click close.
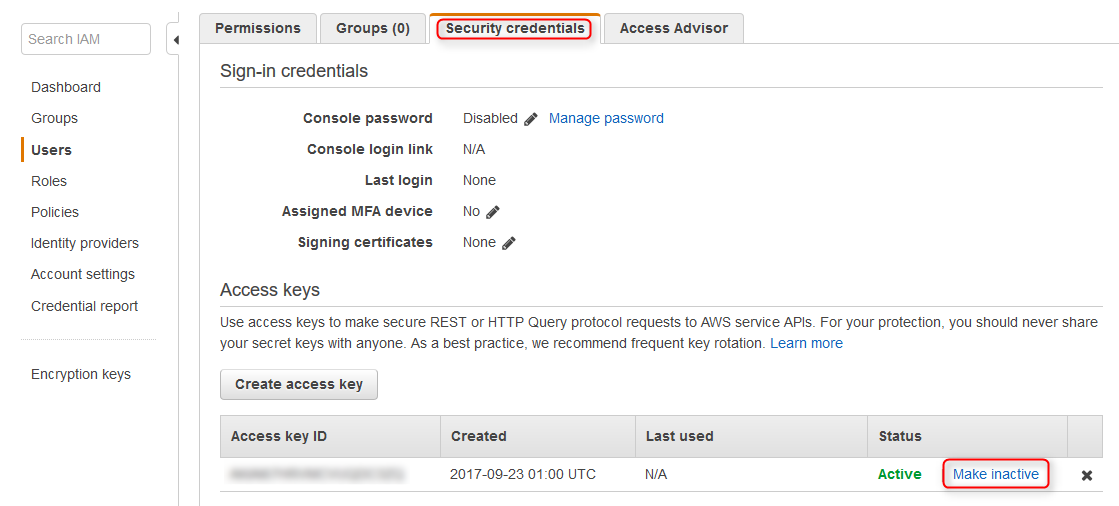
Back in the IAM console under the security credentials tab of the new user disable the IAM keys using the make inactive link.
Further down on the security credentials page locate the HTTPS Git credentials section and use the Generate button. Credentials will be presented in a popup dialog. Save these credentials for later use.
Creating Your First CodeCommit Repository
Back in the AWS services console use the drop down in the top right of the screen to select the desired AWS region to use with CodeCommit. Then search for CodeCommit from the service search bar.
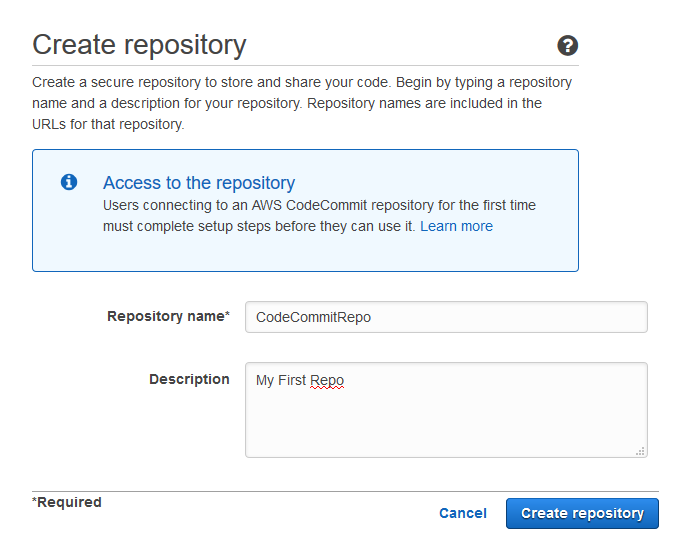
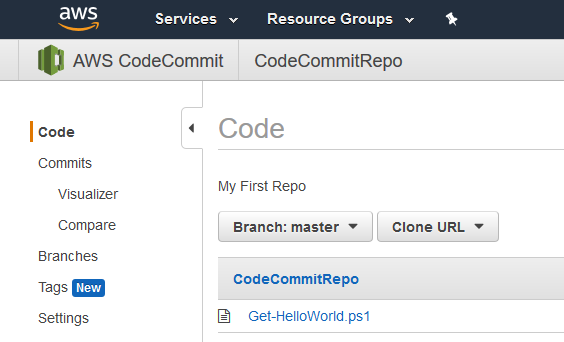
Landing on the CodeCommit service page brings a Getting Started button, clicking the button starts the create repository process. I’ll go ahead and create a repository called CodeCommitRepo in this example.
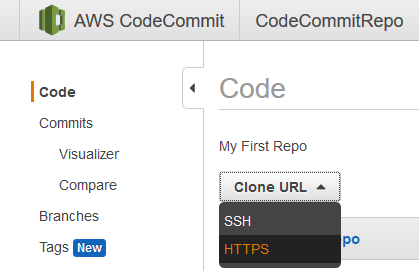
Copy the link that is provided after choosing HTTPS from the Clone URL drop down. Save this link along side the previously saved Git HTTPS credentials.
Cloning a Repo And Making the First Commit
That was a lot of boring prep but now you should have everything you need to start using CodeCommit. If you don’t already have Git installed you will need it. Assuming you are on Windows download and install Git for Windows. The defaults of the installer are fine but make sure to double check the option to ensure the path environment variable will be updated to use Git.
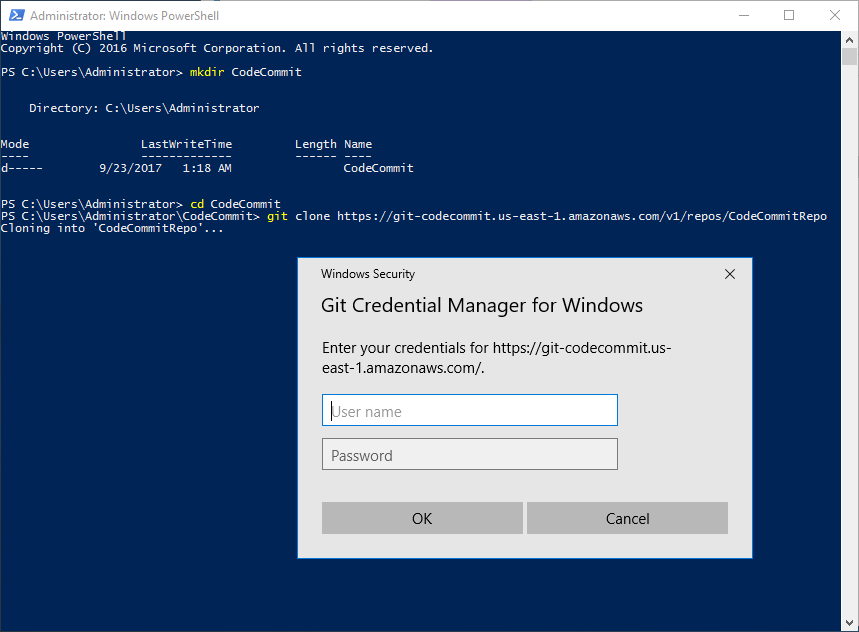
With Git installed I create a new folder to keep the local clone of the new repository. Using PowerShell in this example I create a directory and cd (or set-location) into the new directory. From the new directory I then use “git clone” followed by the Repo url saved earlier.
When Git tries to clone the directory it will prompt for the HTTPS Git credentials.
After entering the credentials Git clones the repo into a new sub-directory. If this is your first time using git set the email and name to attach to commits made to this repo. This can be done with git config within the sub-directory.
PowerShell
1
2
3
cdCodeCommitRepo
git config user.email'chris@example.com'
git config user.name chris
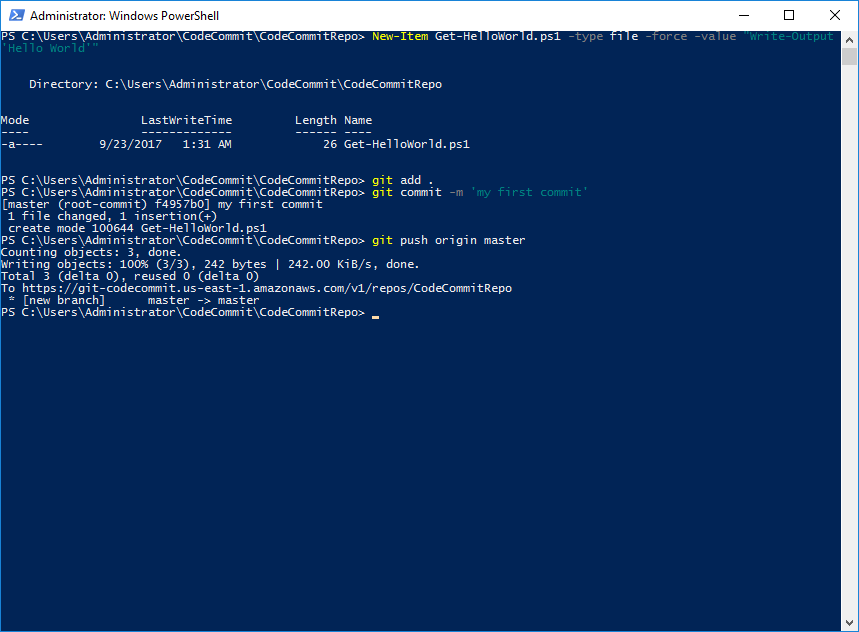
For this walk-through I will create a new script file with PowerShell but I could also copy existing scripts into the directory at this step. Creating a README.md here would also be useful.
Once the files I want stored in CodeCommit are in the cloned repo folder I am ready to start using source control! I use “git add .” to stage all the files in the directory for the next commit. Then “git commit” is used with the -m switch to add a message describing the changes. Finally “git push origin master” sends the commit up to AWS CodeCommit.
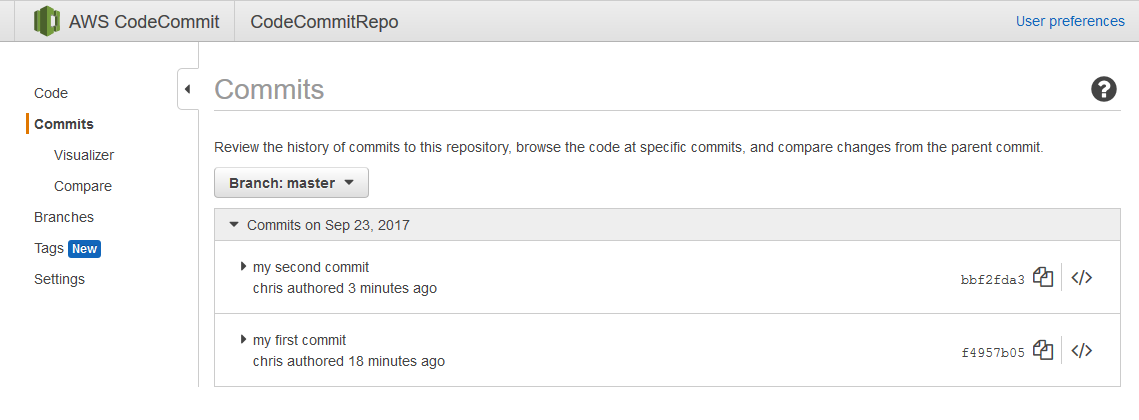
Back in the CodeCommit console will be the newly committed files.
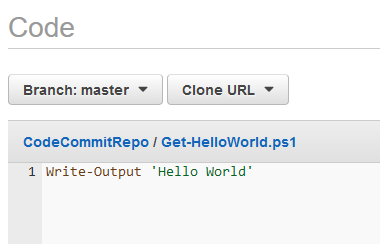
I can now view the contents of synchronized scripts from the console.
Using CodeCommit with Visual Studio Code
Maybe the command line isn’t how you want to work with Git. Its not for everyone. Visual Studio Code has great PowerShell and Git integration and it works smoothly with CodeCommit.
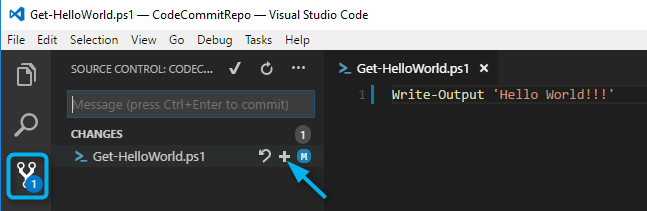
When working with PowerShell scripts in Visual Studio Code it will detect when it is working in a directory that is associated with a Git repo. Here is an example of what happens if I update my Hello World script file. I added some exclamation marks to the script and then saved the changes. The Source Control icon on the left hand side of Code lights up indicating it sees changed files. I can then use the + sign next to the file to stage my changes (git add equivalent).
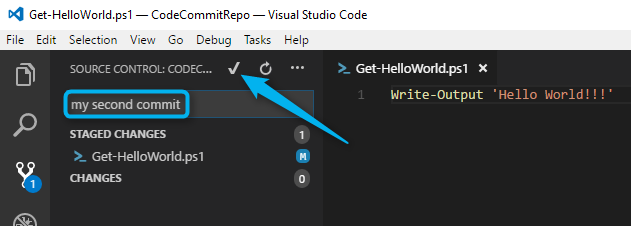
Then with files staged I can add a message and use the check box to commit (git commit -m equivalent).At the bottom of the Window is where I can synchronize changes up to AWS CodeCommit (git push equivalent).
A popup dialog appears for confirmation.
Now back in CodeCommit I can see the commit history and am able to track changes to my scripts.
Summary
In this walk through I created a new IAM user to use with AWS CodeCommit. The new IAM user is left with no access to AWS other then the CodeCommit service through HTTPS authentication. Using HTTPS authentication with CodeCommit enables encrypted file transmission and AWS handles encrypting the storage. Using this solution for source control I gain off site backups and versioning of all my scripts. Best of all its no cost to me provided I can stay under the CodeCommit Free Tier service limits.
AWS CloudFormation is a really powerful service that enables programmatic creation and modification of AWS resources. It is the centerpiece of most AWS “Infrastructure as Code” implementations enabling developers and operations to achieve idempotence with infrastructure.
Common CloudFormation Challenges
Something any newcomer to CloudFormation will discover when starting to learn the service is the sample templates found online will often be outdated. Most CloudFormation templates that are designed for multi region deployment will utilize mappings of AMIs or instance types. These mappings exist to allow the template to take input from stack parameters to achieve different results based on the dynamic input. The latest AMIs for newer instance types change frequently and not all instance types are available in all regions so mappings are used to allow templates to handle as many scenarios as possible. Amazon Web Services is constantly changing and as a result static templates even with well thought out mappings will quickly go out of date as new AMIs are launched into any of AWS’ many regions. Just take a look at Amazon’s whats new page. The speed of change and new features that Amazon delivers is amazing and writing static CloudFormation templates in JSON or YAML just won’t be able to keep up.
Leveraging Amazon SDKs and other third party tools like troposphere can help organizations make better use of CloudFormation. Today I will share an example of how I can use the Amazon Python SDK (boto3) and troposphere to generate dynamic CloudFormation VPC templates that can be kept up to date as new regions and availability zones are added to EC2.
My need for dynamic CloudFormation templates
Something I often find myself doing to keep up with Amazon Web Services is launching spot instances. It is the cheapest way for me to spin up a short lived instance and install a SDK or a new tool I want to try. I want the ability to have VPCs in any region so I can find the cheapest spot instances available for the instance type I want to launch. Spot prices vary by region and availability zone at any given moment and VPCs without VPN connections are free so it is beneficial for me to have launch options in every AZ of every region.
The VPCs I need in each region are fairly simple the requirements are:
An internet gateway attached to the VPC
A subnet created in each availability zone in the region
Network ACLs to allow connectivity to instances in the subnets
Routing from the subnets to the internet gateway for external connectivity
Public IPs assigned to all launched instances by default
The below python script will generate a CloudFormation template that can be used to create a VPC in any available region, using all accessible availability zones in the region. The list of regions and availability zones is queried directly from the AWS APIs. If tomorrow a new availability zone becomes available in any of AWS’s many regions, I can run the template generation script to generate an updated version of the CloudFormation template. The updated template can then be used to update the CloudFormation stack to immediately make use of the new availability zone. The same concept applies to new regions if AWS launches a new region tomorrow I will be able to make use of it immediately without writing any new code.
Walkthrough of using this script to generate a CloudFormation template
Basic Requirements for this script:
Python3 installed and configured
boto3 installed and ec2 describe permissions configured
troposphere installed
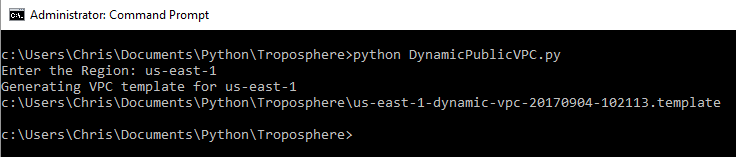
With the above requirements met I can execute the python script to generate a CloudFormation template. The script will prompt for the desired region which in this example I will enter as us-east-1. If an invalid or unavailable region is entered, the script will display a list of valid regions to be used. The script then displays the path to the CloudFormation template that is generated to the current working directory.
With the template generated I can now head to the CloudFormation console in us-east-1 to launch my spot instance VPC stack. It is also possible to use the Amazon SDK’s to launch this CloudFormation template for true Infrastructure as Code but for this example I will be using the console. From the CloudFormation console I click the Create Stack button.
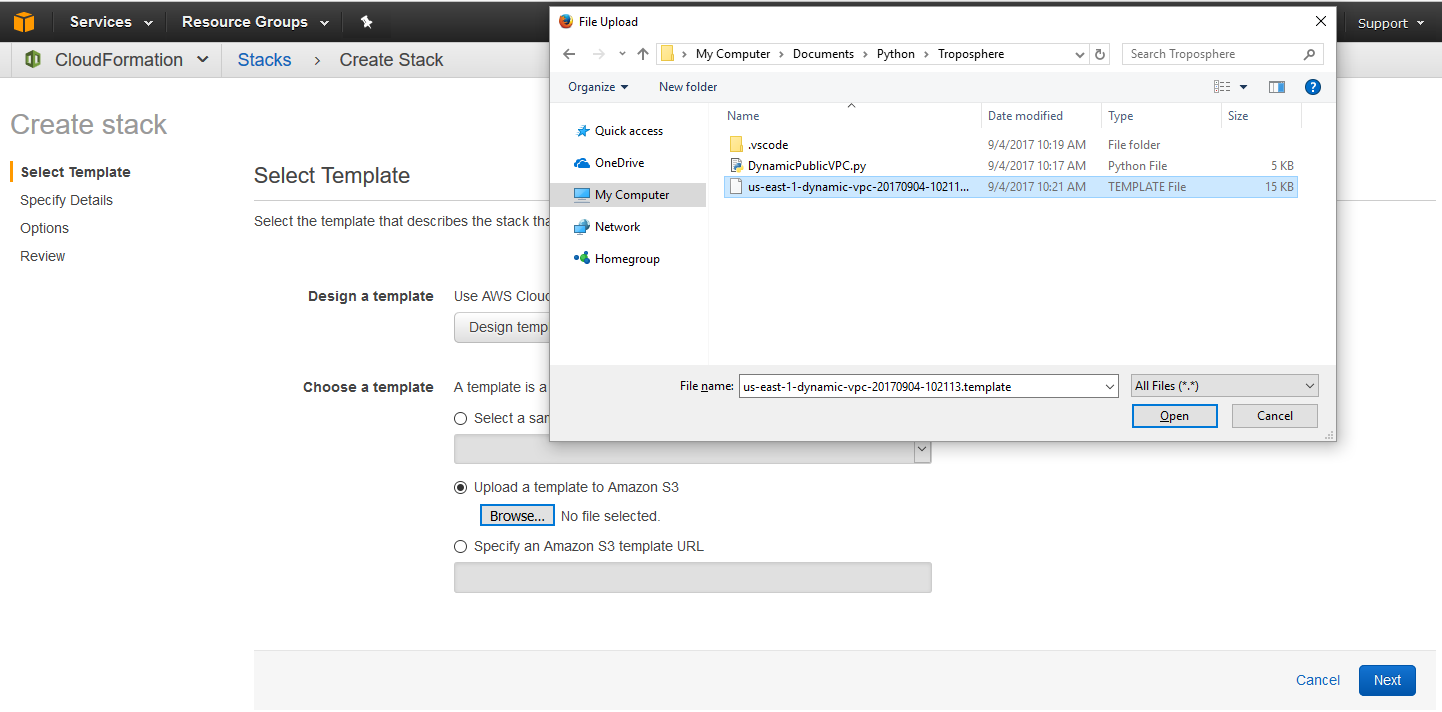
On the next screen I choose “Upload a template to Amazon S3” and click the browse button. Using the file upload dialog popup I can navigate to the file that was displayed from the script execution above and click Open. The file will be automatically uploaded to an S3 bucket for me and its ready to be consumed by CloudFormation to create the stack.
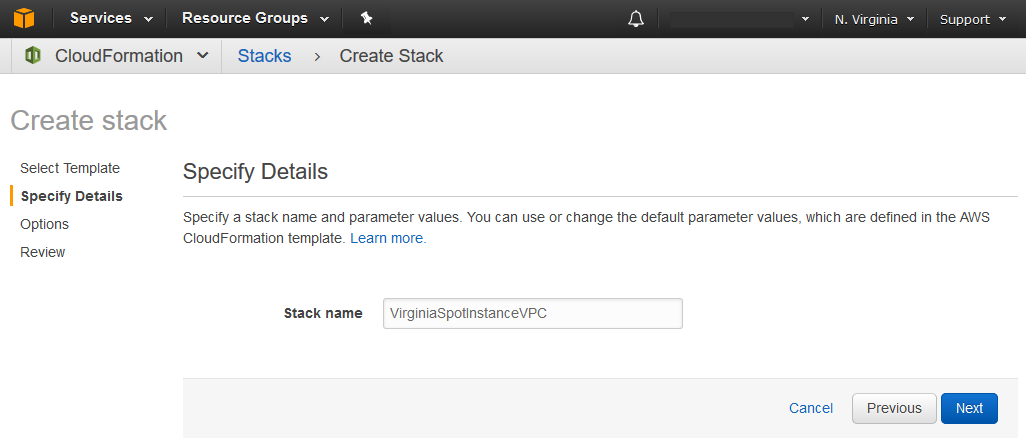
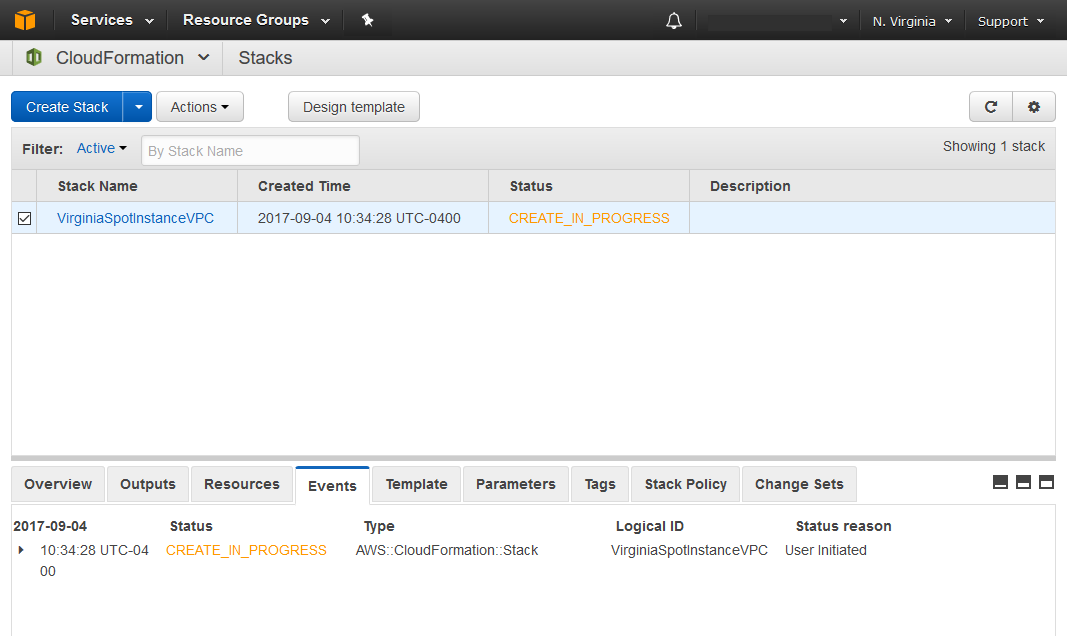
After clicking next I am prompted to input a stack name, lets go with VirginiaSpotInstanceVPC.
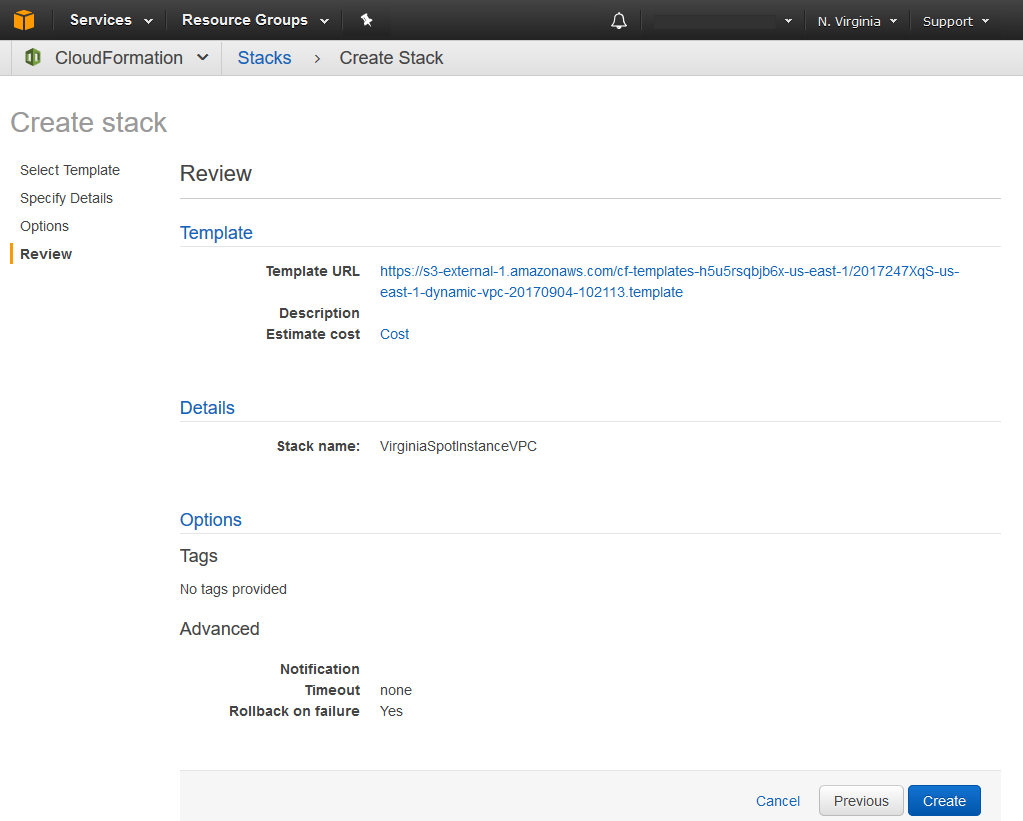
The next screen displays some stack launch options, I am taking the default so I omitted the screenshot. The final step of the wizard is a review page. Everything looks good so I am ready to click create and watch CloudFormation works its magic.
CloudFormation Stack Creation
Once the stack is launched the console will exit the Create Stack wizard and return me to the CloudFormation console where the stack launch status is displayed. At this point the stack creation is still in progress.
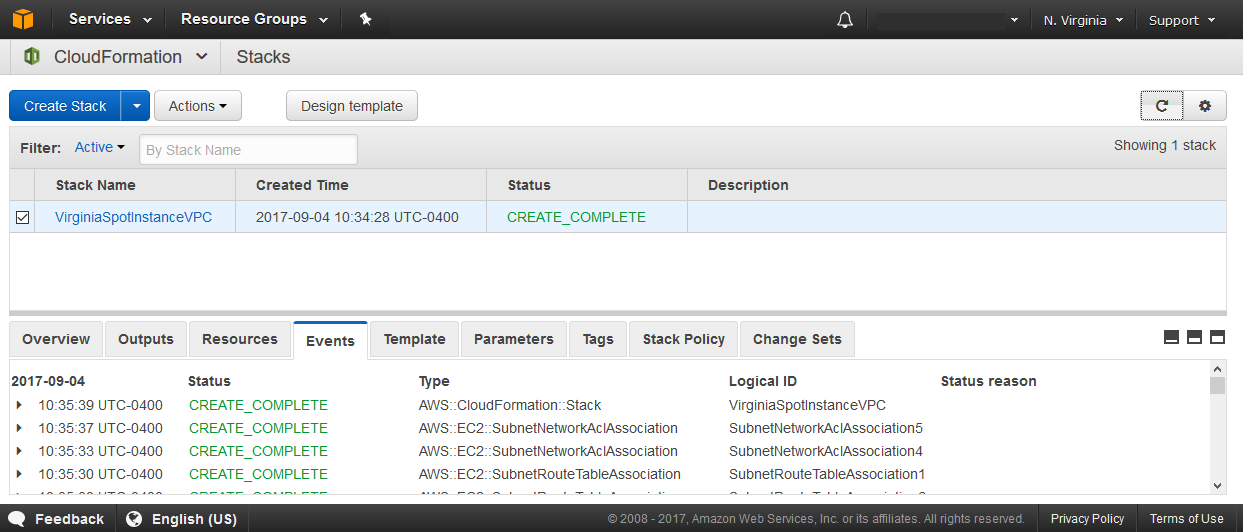
After a minute or so I can utilize the refresh button on the top right of the CloudFormation console to see if the stack creation is done. The events tab can be used to view time stamped logs of the resource types the stack altered.
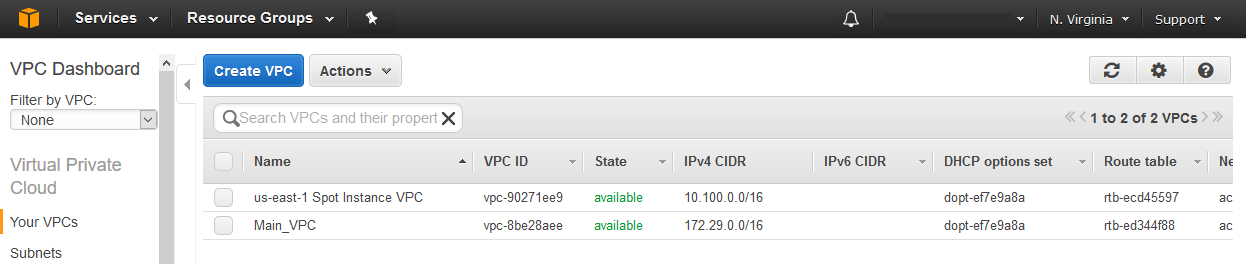
The status is now green / CREATE_COMPLETE so I can go check out my shiny new spot instance VPC in the VPC console of the us-east-1 region.
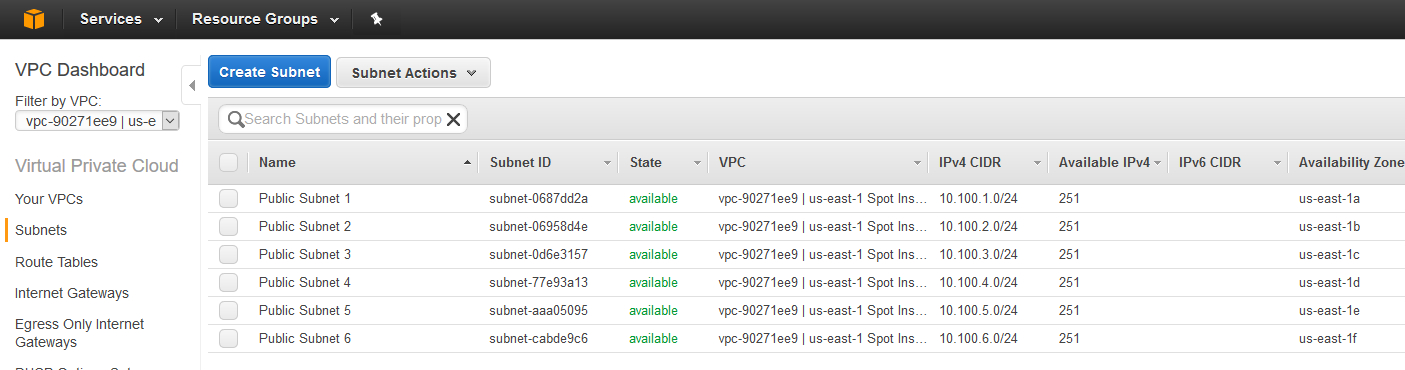
On the left hand side I use the filter dropdown to only display objects that apply to the new spot instance VPC and check on the subnets to make sure I have a subnet in each availability zone in the region. Indeed I do.
Summary
I was able to identify my need for dynamic infrastructure creation and leverage python, boto3, troposphere, and CloudFormation to create templates that should be reusable and update-able for the foreseeable future. The open source troposphere library opens up the possibility of using loops to iterate over returned objects from real-time calls to the AWS APIs with the python AWS SDK. Another benefit of using troposphere is I don’t have to sweat JSON or YAML syntax, I can use my working knowledge of python syntax instead.
Of course nothing is totally future proof in the fast moving field of cloud computing but I think this approach sure beats writing straight JSON or YAML templates and then updating them everytime a new region or AZ is added to AWS.
That wraps it up for this example of using boto3 and troposphere to help manage infrastructure as code.
Below are some of the documentation links I used to create this solution.
One of the things that tripped me up early on while learning PowerShell was working with objects. Like most sysadmins I approached learning PowerShell from a scripting mindset. I wanted to run a script and have the script complete a routine task. I thought about PowerShell as a purely procedural language and I mostly ignored objects.
A great characteristic of PowerShell is just how easy it is to get started. You can still get tons of tasks done in PowerShell without a solid grip on objects. But to make progress into the language and get into what most consider intermediate level knowledge there is a need to gain a solid understanding of objects. How does someone without a programming or developer background get to a solid understanding of objects? I mean there are so many kinds of objects. Its not like there is an arbitrary number of times you pass objects over the pipeline before you have them all mastered. No, the best way get comfortable working with objects is learning how to examine them.
Below are the methods I use the most when working with unfamiliar objects.
Method Number 1: IntelliSense in the PowerShell ISE.
This is my go to method of inspecting a simple object. This often is all that is needed to discover to the properties of the object I am after.
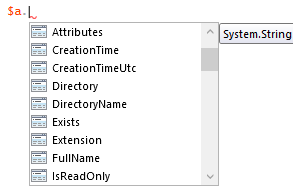
To demonstrate this I will use a practical example of getting the full path to file objects returned from filtering the results of Get-ChildItem. I can save the search results to a variable $a.
With the variable saved I can call the variable with a trailing period and that will start IntelliSense exploration of the object.
This gets me right to the “FullName” property that contains the complete path.
Method Number 2: Get-Member
If using IntelliSense does not get me what I am after, I am probably looking at a more complex object. Maybe its an object that contains other objects. The best way I’ve found to further inspect a object beyond IntelliSense is to pipe it to Get-Member or its alias “gm”.
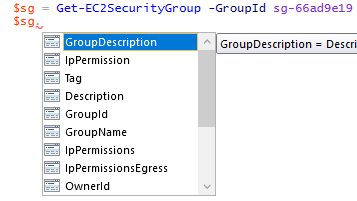
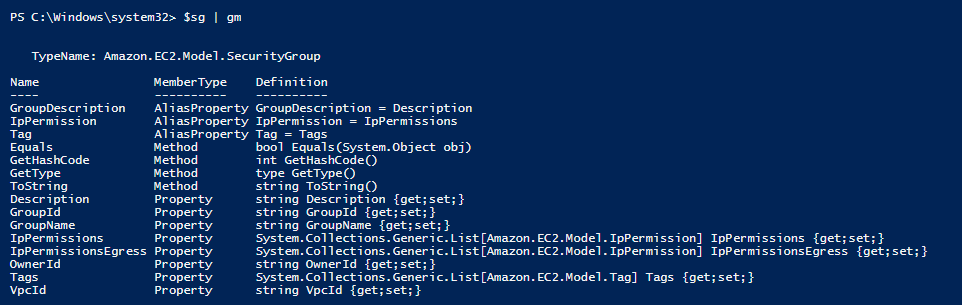
Again I will use a practical example from one of my posts a few weeks back about working with Amazon EC2 security groups. My goal in this example was to create security groups and their inbound/ingress rules. I know from experience that I want to understand Amazon’s objects when working with the AWS Tools for Windows PowerShell before using the cmdlets. So I set out to look at what kind of objects Amazon uses for its EC2 security groups. My first step was to look up a security group with the Get-EC2SecurityGroup cmdlet and save the returning object to a variable.
PowerShell
1
$sg=Get-EC2SecurityGroup-GroupIdsg-66ad9e19
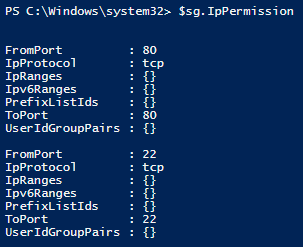
With the object stored in the variable I tried IntelliSense and saw IpPermission properties that looked promising. I have a hunch that this property will reveal how security groups handle their network traffic permissions.
After choosing the property and entering it into the console, I can see it does contain what I am after but its not so straight forward. I see some “{}” in fields where I expect data. Port 80 and 22 match up with my ingress rules on the security group but there are no details on the source security group of the ingress rule.
This is a sign of a more complex object and its time to use Get-Member.
PowerShell
1
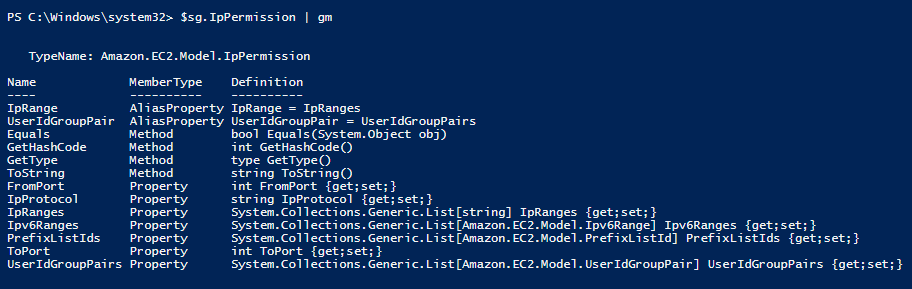
$sg.IpPermission|gm
Whoa, this object is quite complex. I can see that this IpPermission property that I am inspecting is an object type unique to itself. Its an Amazon.EC2.Model.IpPermission which is listed at the top of the Get-Member output. This IpPermission has its own set of properties. I think of these as “sub-properties” from the parent security group object. Looking at these “sub-properties” we see they are lists of other object types. Its only going to get more complex from here!
Next I backtrack a step and pipe $sg to Get-Member and see that it is an Amazon.EC2.Model.SecurityGroup.
PowerShell
1
$sg|gm
With the type of the object gained from using Get-Member, I can use a search engine to find my way to Amazon’s documentation of this object’s class. That’s another great source of information about this object. From this point further inspection is a matter of preference. I can keep using Get-Member on all the properties under IpPermission to learn about the object or I can look to Amazon’s documentation about the IpPermission class. Both of these options are valid but I prefer to keep using PowerShell. Continuing down this path of discovering sub properties and piping them to Get-Member might take a while so to save time I can move on to my final and new favorite method of object exploration.
Method Number 3: Show-Object
Show-Object is a great add-on to PowerShell. Its available from the PowerShell gallery as part of Lee Holmes’ PowerShellCookbook module. Its like Get-Member on steroids.
PowerShell
1
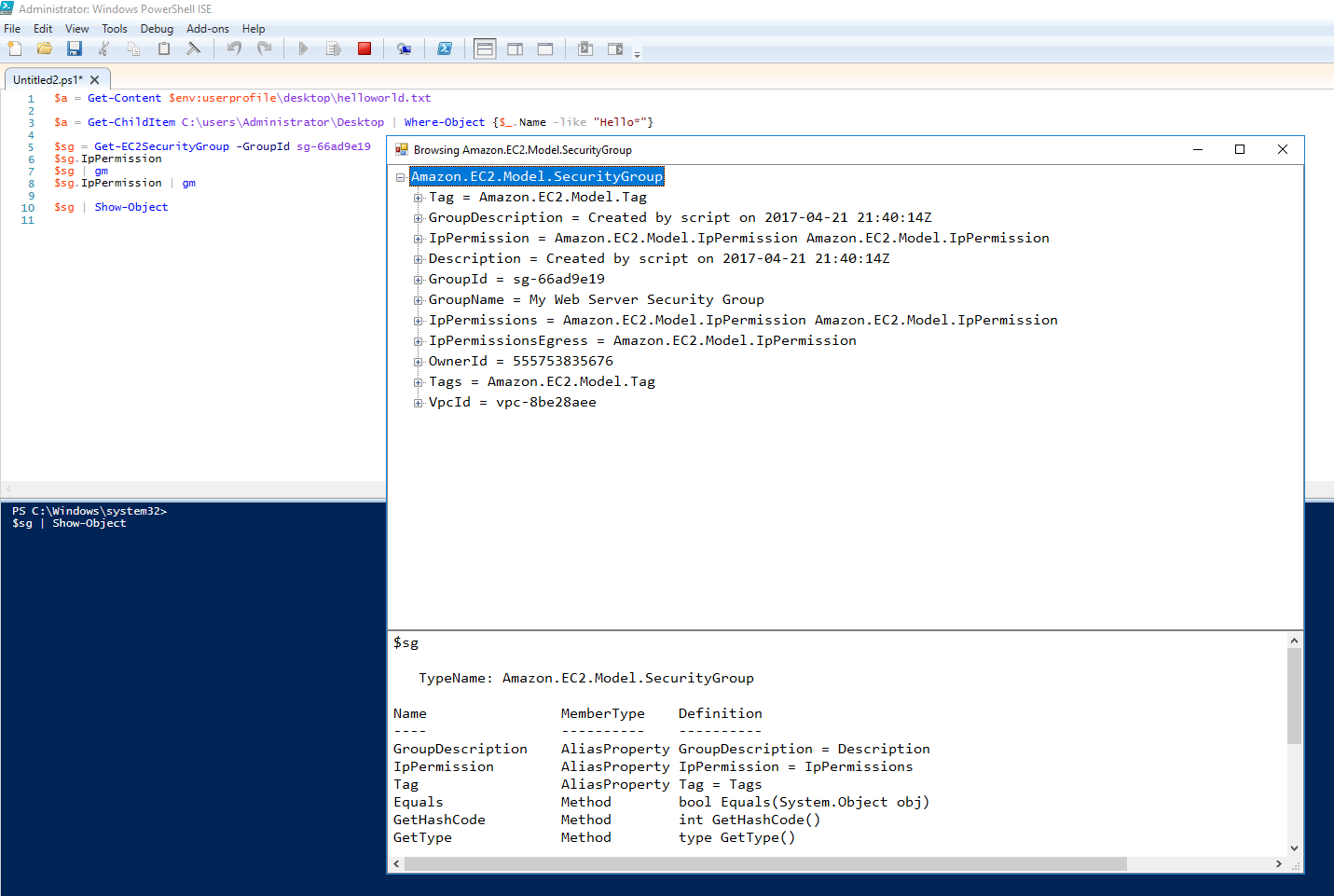
$sg|Show-Object
When you pipe an object to Show-Object it will display a tree view of the object in a GUI just like showwindow. You can use the popup window to click through all the properties of the object and discover more details about the object’s inheritance and structure. As you drill into the tree view the bottom pane of the window will update with familiar Get-Member results of each property.
A few clicks later inside the IpPermission property I see information about UserIdGroupPair and I’ve found my source security group allowed for ingress traffic. This is “sg-fda89b92” in the image above. It is in a form I did not initially expect. With all the information I have gained from these discovery methods its was only a matter of time before I had a great understanding of this previously completely unknown object type.
I wanted to look at connecting two disparate systems for a recent project. The goal was to be able to enter information into one system and have information processed by another system. The systems have no direct authentication trusts between them but they are both running on Amazon Web Services EC2 platform. This was a perfect use for the decoupling nature of the Amazon Simple Queue Service and I wanted to come up with a proof of concept, which is outlined below.
Before getting into any details, I want to make clear that this is not a best practice use case of SQS. For most uses of SQS there is a need to keep track of the messages being processed in some kind of permanent state such as a database. With a persistent data store containing the processed messages, the queue workers can more effectively process messages if messages are delivered one or more times. That being said lets go over this proof of concept.
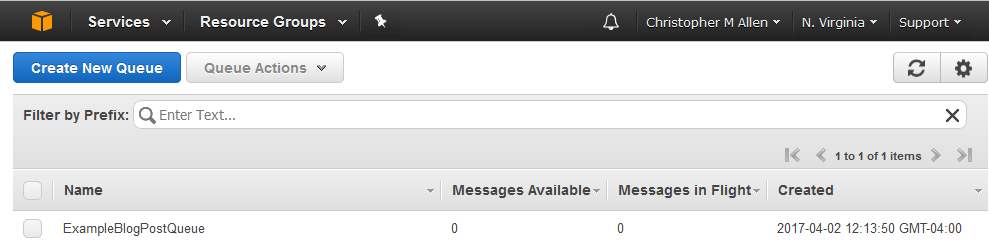
Assuming AWS keys with correct permissions are configured and the AWSPowerShell module is loaded, the below command will create a new SQS queue with PowerShell. The command returns the created queue url which will be stored in a variable $NewSQSQueueUrl for future use.
A quick peek at the SQS console to ensure the queue was created.
This next bit creates an array of strings which will serve as some example information to share between the systems. For this proof of concept I am sending example PowerShell parameters into the SQS queue.
PowerShell
1
$exampleparams=@("All The Things","Another Example Parameter")
I have written the POC functions which are also uploaded to my GitHub PowerShell repo that get dot sourced. These functions put the information (example parameters) into the new SQS queue as message attributes of the newly created SQS message.
After running these functions the message ids are returned to the PowerShell host indicating the messages have been inserted into the SQS queue successfully.
Below is the function that was dot sourced that did the uploading. You could customize this to fit your use case with some help from the AWS Send-SQSMessage cmdlet documentation.
Send-SQSMessage-QueueUrl$SQSQueueUrl-MessageAttributes$messageAttributes-MessageBody"Request generated by $($env:Username) at $(Get-Date -Format u)"
}
}
catch{
Write-Error$_
}
}
}
With messages being put into the queue, I need a function to pull down the messages and process them on the queue worker system (aka the SQS message receiver). My goal is to take different actions on the queue worker system based on the message attributes of the SQS messages pulled out of the queue. That function looks something like this.
Start-SQSQueueProccessing
PowerShell
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
functionStart-SQSQueueProccessing
{
[CmdletBinding()]
[Alias()]
[OutputType([int])]
Param
(
[Parameter(Mandatory=$true,
ValueFromPipelineByPropertyName=$true,
Position=0)]
[String]$SQSQueueUrl
)
Process
{
try
{
Write-Verbose"$(Get-Date -Format u) Polling for $SQSQueueUrl messages"
}else{Write-Verbose"$(Get-Date -Format u) ... No messages were pulled from the queue...nothing to do right now"}
}
catch{
Write-Error$_
}
}
}
This function isn’t actually doing anything interesting with the messages other than generating some output to the PowerShell streams but this is a proof of concept after all :).
Considerations when using SQS
As SQS is designed to decouple distributed systems, SQS does not assume every message pulled from the queue has been processed successfully. Messages that are pulled from the queue are hidden from the queue until the message visibility timeout period has passed. It is up to the queue workers to delete the messages from the queue after the message has been processed. This is why at the end of the function above, messages are deleted from the queue with the Remove-SQSMessage cmdlet.
After working with SQS a bit, I noticed that the behavior surrounding the delivery of messages sitting in the queue is a little unintuitive. For example, say there are 8 messages in a queue and I request for up to 10 messages to be received with Receive-SQSMessage. A logical assumption would be that all 8 messages are returned but that is rarely the case. After working with some messages in queues it becomes quite apparent that SQS will return a random number of messages. Additionally without using FIFO (First-In First-Out) queues, the messages will often be delivered out of order.
Another bit of a gotcha I ran into at first was that by default, Recieve-SQSMessage will not return any message attributes from SQS. The resulting Amazon.SQS.Model.Message object that was returned had blank MessageAttributeValues until I specified “-MessageAttributeName All” parameter.
Hopefully the above considerations will shed some light on the way the function is written. I wrote it so that it could be run repeatedly from a parent polling script and that it could handle one more more message objects being returned from each poll of SQS.
Back to the functions
Finally, we get to the polling function portions of the script which could run on scheduled intervals via task scheduler. This function first checks a queue for the existence of messages using the Get-SQSQueueAttribute cmdlet. If messages are found in the queue, it will invoke the Start-SQSQueueProcessing function referenced above to handle the messages. I make use PowerShell transcription to keep a log for now. If this ever moves out of proof of concept, logging could be improved quite a bit to make it cleaner.
What does it look like when ran you may be wondering?
The PowerShell transcript output captures the same information. As you may have noticed, the body of the generated SQS messages contains information on who created the SQS message and when it was created which could help for audit trails.
Here is some example code which may help you automate security group creation with PowerShell. I wanted to take a look at automating some security group creation tasks today and there wasn’t too much help available via search engines. Maybe this post will help that out a bit.
The minimum amount of IAM permissions needed to accomplish this task will be:
IAM Policy for this script
Vim
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"Stmt1392679134000",
"Effect":"Allow",
"Action":[
"ec2:Describe*",
"ec2:AuthorizeSecurityGroupIngress",
"ec2:CreateSecurityGroup",
"ec2:CreateTags"
],
"Resource":[
"*"
]
}
]
}
This snippet of powershell will:
Lookup the only VPC in your account, provided your regional defaults are set via Initialize-AWSDefaults or the ec2 instance you are running this on. This is helpful as some of the powershell cmdlets only play nice with the default vpc, which many people tend to delete.
Create a new security group for a load balancer
Allow HTTP and HTTPS traffic ingress into the load balancer security group
Create a new security group for a web server
Allow HTTP from the load balancer to the web server security group
Allow SSH from a security group that is looked up by the name “My Bastion Host Security Group” to the web server
Today I am going to attempt to take some PowerShell functions I wrote on Windows and run them on Linux. This should all be possible now that Microsoft Loves Linux! With the new .Net (core) going open-source and cross platform combined with AWS’s Tools for PowerShell core, I should be able to run the exact same functions across Windows and Linux.
For this exercise I will be using a Ubuntu virtual machine on Hyper-V but this could easily be done on CentOS or other various linux distros. Microsoft recently added support for installing PowerShell through popular distro’s default package managers so we will take that approach to get up and running.
Enough intro lets get to it! I am going to use Microsoft’s provided steps in a bash terminal window to register the Microsoft repo and get the latest PowerShell 6 alpha installed and running.
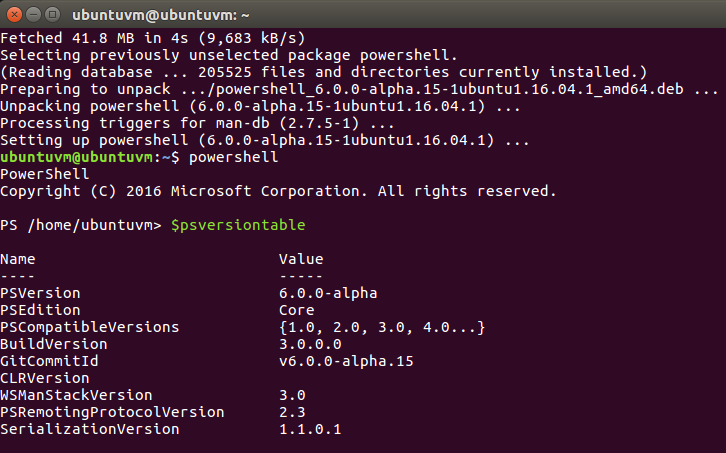
After running those commands, PowerShell is installed and the system leaves us at the PowerShell command prompt.
To verify everything is working I can use $psversiontable to output our PowerShell info to the host.
Okay, everything is looking good so far.
Loading AWS Tools for PowerShell Core
Next up is to get AWS Tools for PowerShell core loaded. This can be done with the new PowerShell package management cmdlets specifically Install-Module.
PowerShell
1
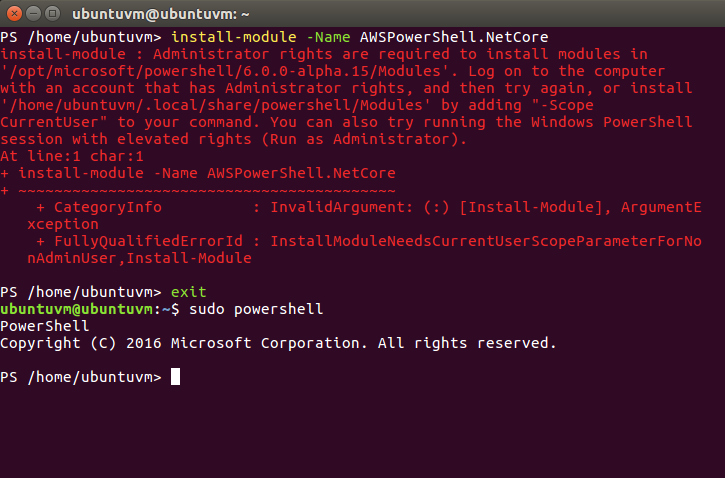
Install-Module-NameAWSPowerShell.NetCore
Oh No, a red error appeared! Quick, email this error to our System Administrator to figure out what went wrong! Haha, just kidding. Lets read it.
The error says administrator rights are required to install modules. The suggestions are to try to change the scope via parameter or to use elevated rights. Well, run as administrator sure won’t work on Linux, so I will do the equivalent and exit out of PowerShell then sudo powershell back into the PowerShell host.
After a retry of the Install-Module command from the now elevated PowerShell host, the Install-Module command completes without error.
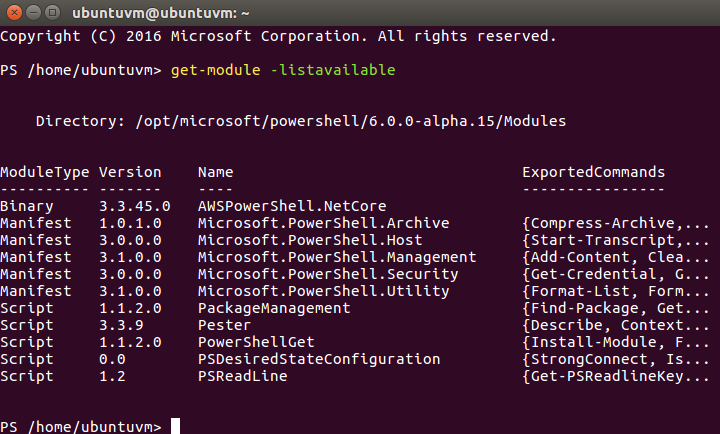
I want to check to see the available modules with the get-module command and verify the AWSPowerShell.NetCore module is listed now that its installed.
PowerShell
1
Get-Module-listavilable
Everything checks out and the AWS module is listed right at the top.
Loading my AWS functions from GitHub
I don’t plan on doing any editing of my functions or commits from this system, so I can skip configuring Git and just install it right from the package manager. The neat thing about using Git is that all the nuances that come from working on files between *nix and Windows, like different carriage returns, should be handled behind the scenes by Git.
Shell
1
sudo apt-getinstall git
Once git is installed I can clone the PowerShellScripts repository from my github.
A quick ls and cd is used to make sure the AWSFunctions folder came down with the repository.
Creating AWS Read Only Access Keys
Since this is just a proof of concept exercise, I am going to run a function I built to check the status of a running EC2 Instance by looking up its Name tag. The only access I need for this in AWS IAM is the ability to describe my instances so we can create a new IAM User with an attached EC2 Read only policy.
The IAM console has really become simple to use with recent updates but lets cover everything step by step.
First I’ll log into my AWS account and navigate to the IAM console. From there I want to choose Users and then use the Add User button.
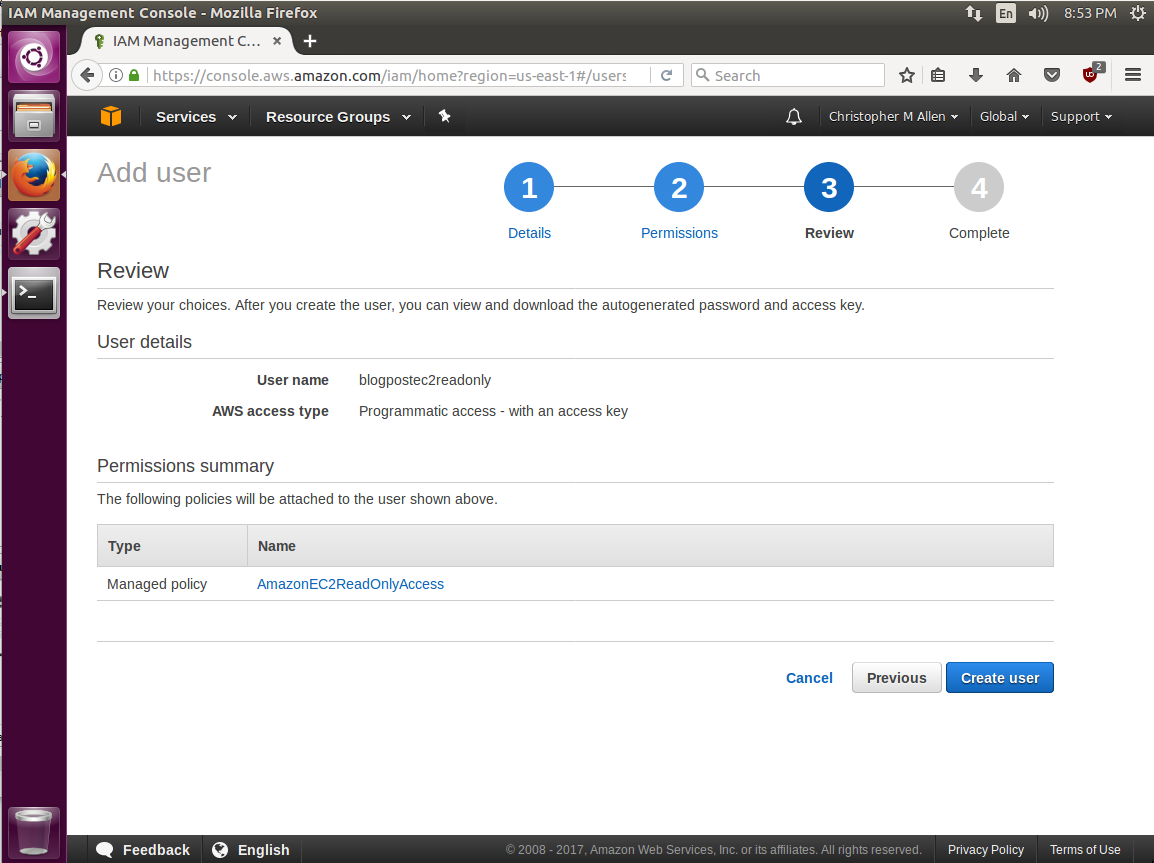
I will call the user blogpostec2readonly and check the box for programmatic access, which will generate our access keys.
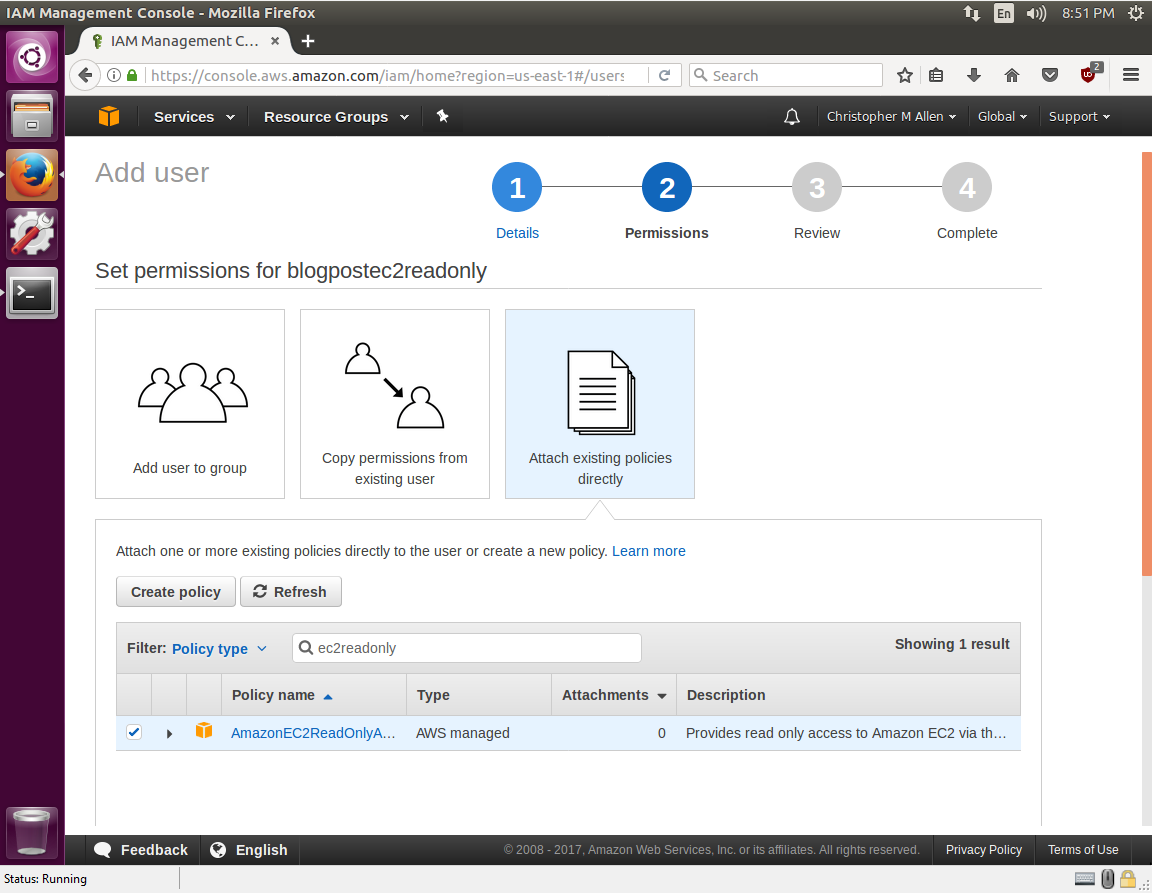
On the next screen I will choose Attach existing policies directly. The filter box directly below can be used to search for “ec2readonly” and an AWS managed policy for EC2 Read Only will appear. This managed policy is prewritten json IAM policy maintained by Amazon that helps administrators quickly provide permissions without needing to deep dive into IAM permissions. Perfect for our use case at hand. I’ll check the box for this policy and click next.
The next screen is a review screen and a final Create User button.
After the new IAM user is created the access key and secret key are provided for download. Be careful with these, as AWS access keys are all that is needed to access an AWS account. I will copy the provided access keys into the gedit text editor so I can use them in the next step.
Configuring AWS PowerShell Module Credentials
All the prep work is nearly completed and the next steps are to configure the default region, access key, and secret keys to be used with the AWS PowerShell module cmdlets. To do this we will import the AWSPowerShell.NetCore module and run the Set-AWSCredentials and Initialize-AWSDefaults cmdlets.
I need to load my functions into memory so lets use Get-ChildItem to list the functions files and dot source each one. (% in PowerShell is a shorthand alias for ForEach-Object)
PowerShell
1
Get-ChildItemAWSFunctions|%{.$_.FullName}
To verify my custom functions are loaded and ready to execute we can try to tab complete them. The function I am running in this exercise is Test-RunningEC2InstanceByServerName so I will type Test-Run and press tab.
Success! Tab completion filled out the name of function for me. Lets see if it works…
The Instance hosting this here blog is called PACKETLOST02 so I will send that server name in as a parameter into the function and I am expecting it to return that the instance is running.
The function ran and returned that the instance is running.
Summary
How neat was this? I took some PowerShell functions I wrote on the Windows platform and commited them into my GitHub repo then got them to run on Linux. When I initially wrote these functions it was to help automate my day to day administration of Amazon Web Services. I wrote these functions on the Windows platform with only the Windows platform in mind. Thanks to the great work of the developers at Microsoft and Amazon Web Services these functions are now cross platform.
I hope this post provides a quick glance into how useful and flexible PowerShell can be as well as how promising the future of the .NET core and the .NET standard libraries are to cloud computing. Cheers!
So I followed this AWS blog and this documentation to launch a tiny t2 elasticsearch cluster to visualize VPC flow logs. Those links have instructions that guide you along setting up flow logs to flow into ES in a few different ways. I ended up following the documentation link and then downloading some kibana3 dashboards until I found one I liked.
Over time however, the little t2 ES cluster could not keep up, and I ran out of storage space and CPU credits. So I wanted to automate the deletion of indices / indexes so that the cluster would free up storage space and not churn through CPU. With more RAM available the cluster uses less CPU, so I had to limit how much data the single node ES cluster is storing. There is plenty of documentation online on how to use curl to delete elasticsearch indexes but I’m on windows most of the time so I decided to write a quick a powershell script to do it.
To use this script just update the esdomain variable to point to your ES cluster name. Also this filter will only work if the lambda script is creating cwl- indexes. Tweak it if your indexes are different. Run it and it will keep the last 2 weeks of indexes and delete anything older.
So I finally decided to run my own Linux server and utilize the AWS free tier for a year.
It was a great learning experience and I wanted to share the most difficult part of the process, backing up my new blog to S3. Automatically of course.
I had just finished configuring my sever how I wanted. I followed these great guides I found on the net to get me up and running.
After I wrote a few posts and configured some plugins on this here blog it was time to figure out how to automate Linux. Something I have never done before.
Step 1) Generate a script to take backups of my site.
This wasn’t easy, and took a few hours of my time. Over an hour of which was finally tracked down to starting my .sh file on a windows system (using notepad++). Apparently the carriage return character on Windows and Linux is different and there was something in this file that made all my files get generated with ‘?’ in the file name. When I tried to download the files being created by the backup script in WinSCP I was greeted with invalid file name syntax errors. It wasn’t until I ran the bash script with sudo that an prompt appeared upon file deletion showing me ‘\r’ was in the file name and not a question mark.
Once I FINALLY tracked down the root cause of my file creation issues I was off to the races. Thankfully during all this I got the hang of Nano (after admitting temporary defeat learning VIM) and was able to easily create a new shell script file from the ssh window and get my script working. Below is the code I ended up with. Mostly based off this LifeHacker article.
Actually starting Step1:
So here is what you need to do to configure automatic WordPress backups to S3. My approach is to backup weekly and keep 1 month of backups on the server and 90 days of backups in S3.
I started off by making a /backups and /backups/files directory in my ec2-user home directory. This folder will hold my scripts and backup files going forward. This is the directory you will be in by deault after you SSH into an amazon linux instance as ec2-user.
Shell
1
2
3
4
mkdirbackups
cdbackups
mkdirfiles
nano backups.sh
With Nano open, copy and paste the below code into nano. Then press Control+X to save the file.
backups.sh
Shell
1
2
3
4
5
6
7
8
9
10
11
12
13
#!/bin/bash
#this is a variable to hold the date and time to be used in the files
_nowvar=`date+"%m_%d_%Y"`
#mysql backup command - you can utilize the same database user that you configured wordpress with
Once the backups.sh file is created, we need to give it execute privileges.
Shell
1
chmod+xbackups.sh
Now we can run it to make sure it works with bash. Or move right onto scheduling it to occur automatically as a cron job.
Checking it with bash:
Shell
1
bashbackups.sh
Step 2) Configuring the script to run automatically
Scheduling it with cron:
First things first for me, scheduling cron jobs is done with crontab. Crontab’s default editor was VIM which is very confusing to a Linux novice such as myself. Lets change the default crontab editor to nano…
Shell
1
$export EDITOR="nano"
And now lets configure our backup shell script to run Sunday mornings at 12:05 AM EST (0505 UTC).
Don’t forget to Control-X to have nano save the edited crontab file. It appears as Amazon Linux automatically elevates to sudo to accomplish crontab changes because I configured everything without sudo.
Now our site is backing up automatically. So lets offload these backups to S3.
Step 3) Syncing the automatic weekly backup files to S3
Create an S3 bucket. Then create an IAM user, assign it to a group, and give the group the following policy to restrict it to only having access to the new bucket. Replace the bucketname as needed.
Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":["s3:ListBucket"],
"Resource":["arn:aws:s3:::YOURNEWBUCKET"]
},
{
"Effect":"Allow",
"Action":[
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource":["arn:aws:s3:::YOURNEWBUCKET/*"]
}
]
}
Or you can just use your root IAM credentials, whatever floats your boat.
Next up, install s3cmd onto your Amazon Linux instance. While s3cmd is very useful, its third party developed and not an actual Amazon command line feature, so we have to download it from another repository. We can install s3cmd onto an Amazon Linux instance with the following command.
Shell
1
sudo yum--enablerepo epel install s3cmd
You will have to accept some certificate prompts during the install.
Once s3cmd is installed we can configure it with our IAM credentials. Don’t worry, with proper restricted IAM credential setup it will fail the configuration check at the end.
Shell
1
s3cmd--configure
Create a shell script to sync our backup files to s3. Make sure we are still in the backups directory and use nano to create the script.
Shell
1
nano sendtos3.sh
Paste the following code into nano and press Control-X to save. Don’t forget to change the bucket name.
Now you can use some of the steps above to execute the script manually to make sure it works or schedule the script to run a few minutes after the backup script via cron.
You can check the logfile with tail for more information.
Shell
1
tail/home/ec2-user/backups/s3_backup.log
Wrapping it up
At this point you should have your compressed WordPress database backups and compressed Apache files being created weekly. Then they are being synchronized to S3 shortly after. What if we want to keep the files on S3 longer than the files on the server?
All we need to do is enable versioning on the bucket. Then apply a lifecycle policy to permanently delete previous versions after 60 days. Now we have 90 day backup retention.
Anyway, I hope this helps. I tried to link to all blogs that helped me get up and running.